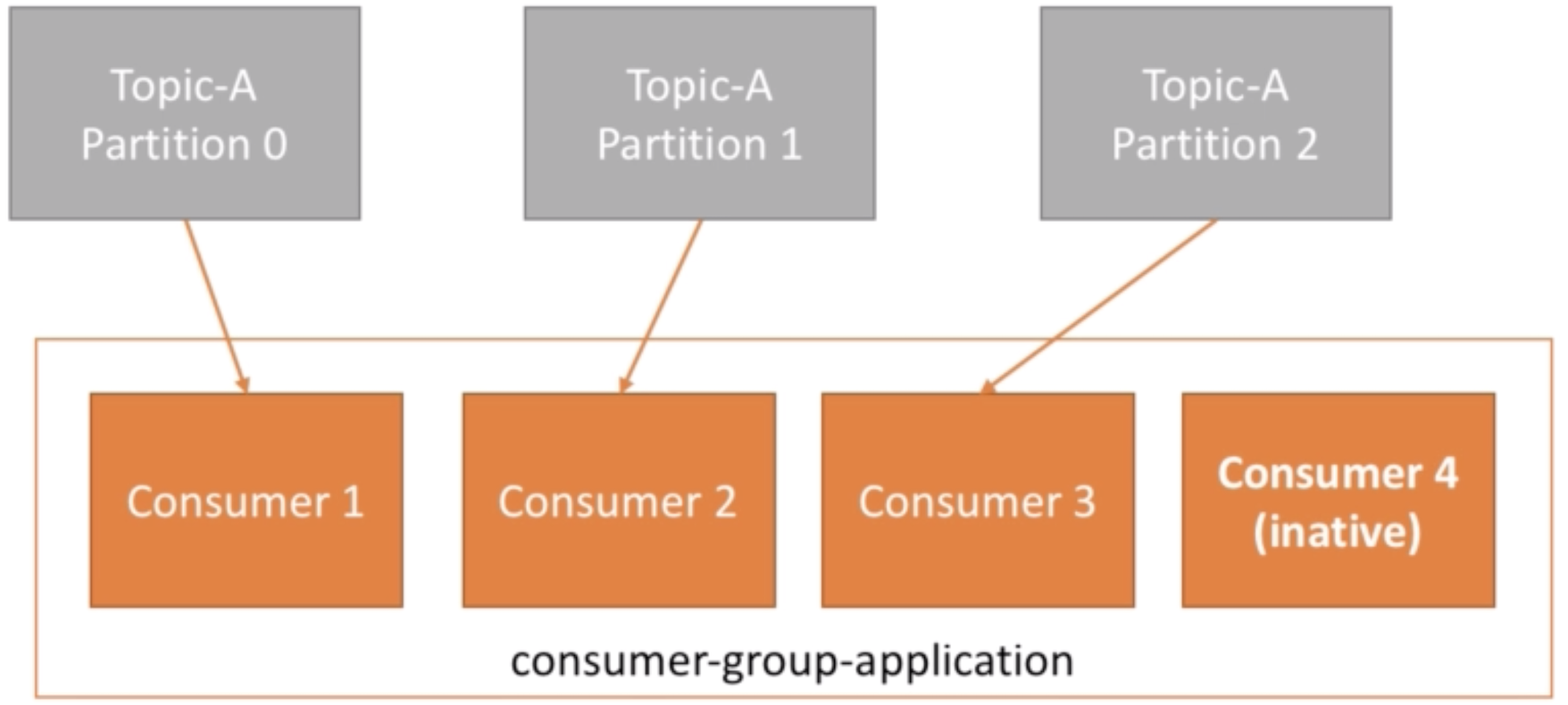
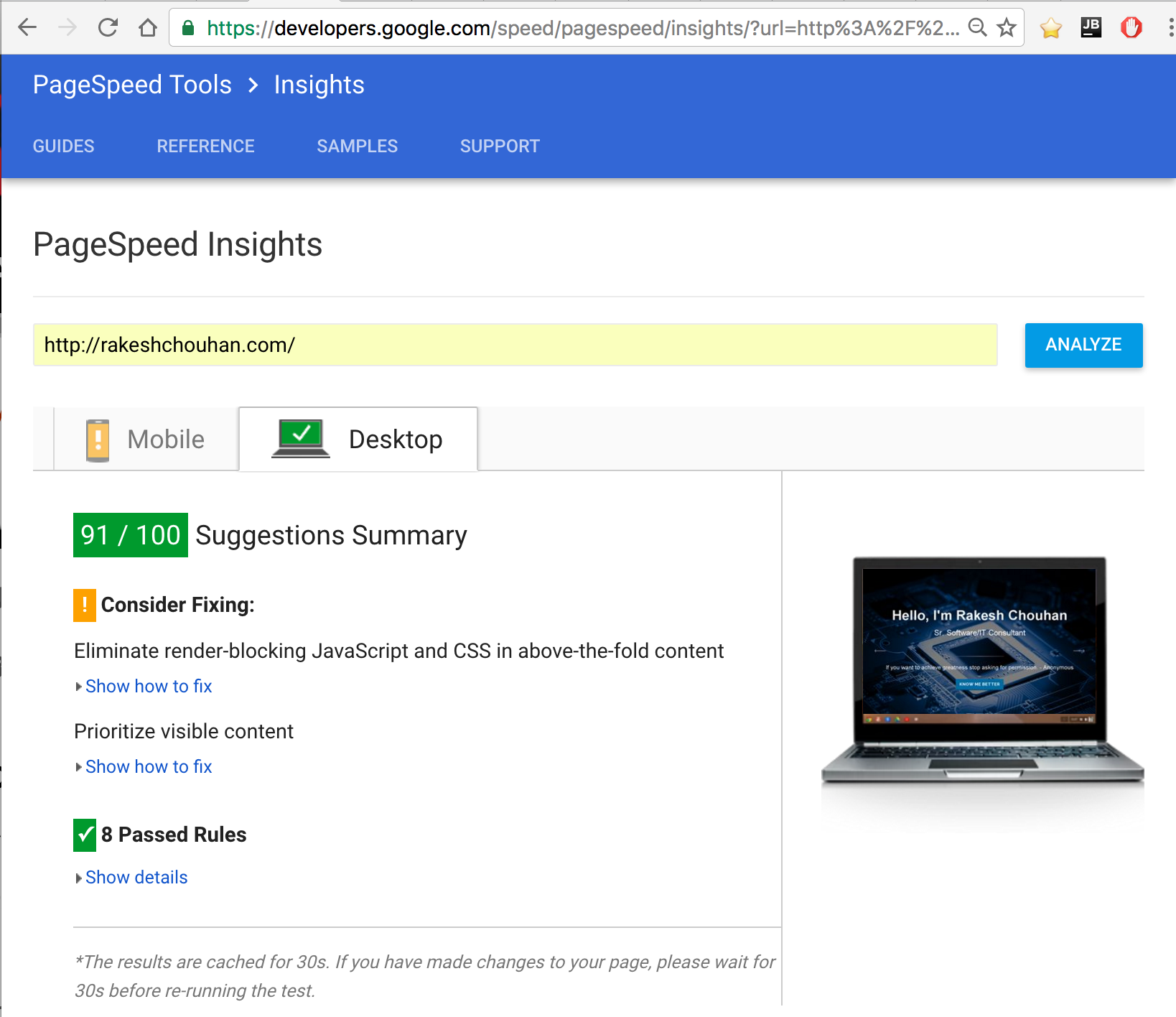
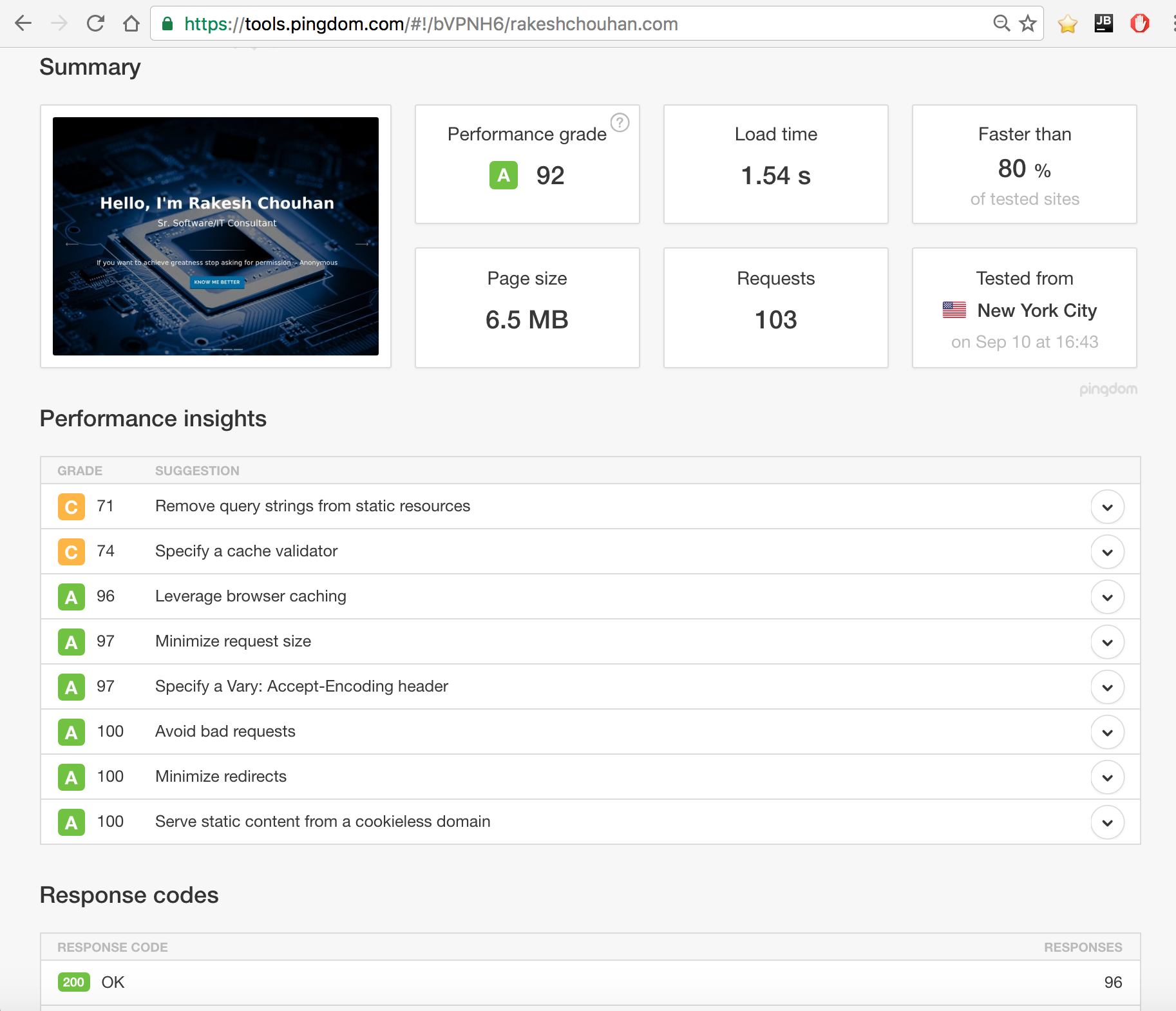
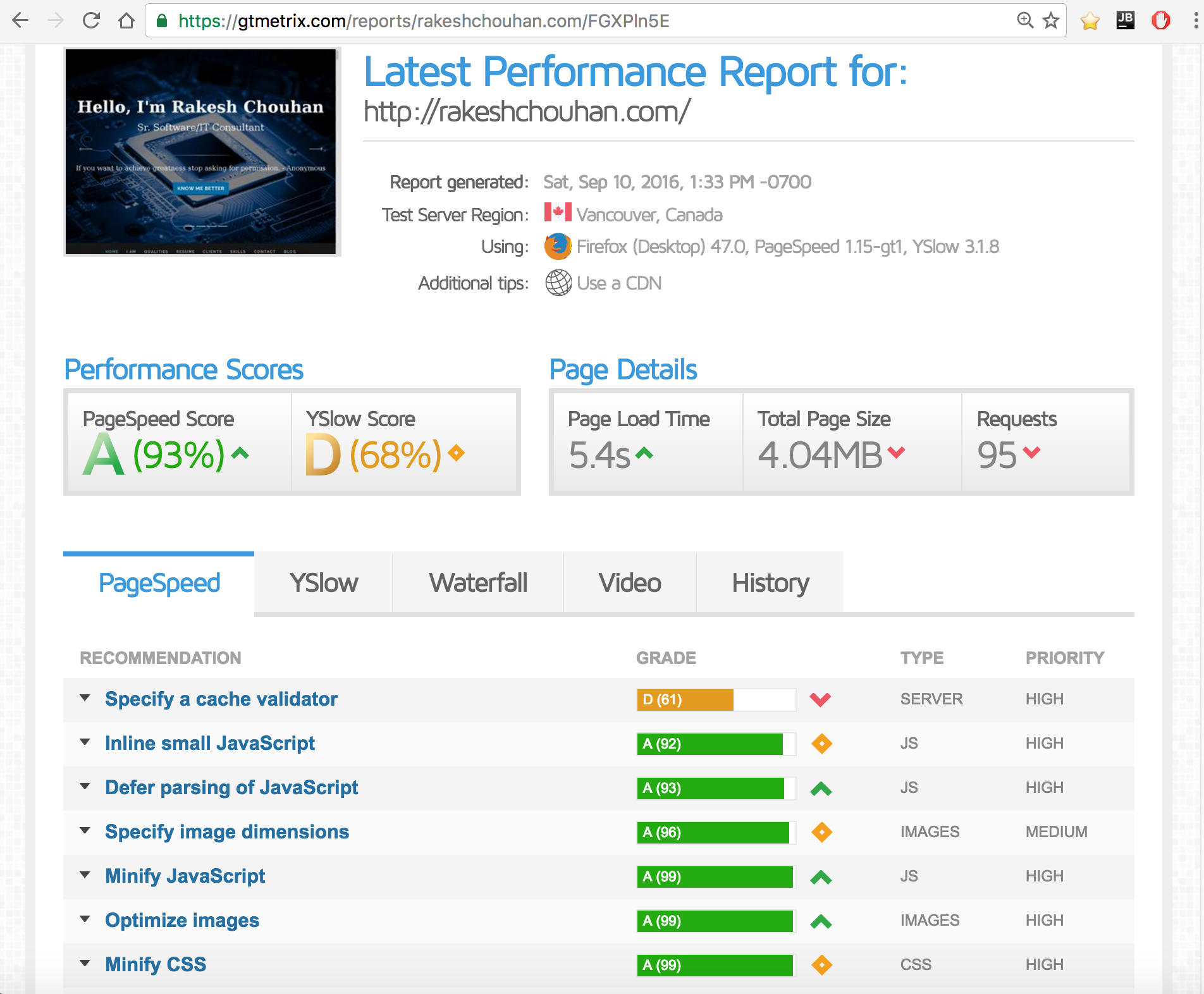
Regular Equality vs Strict Equality.
{} === {}
false // Even though they are empty objects, strict equality not only checks for type & value, but also checks the created instance. The created instance is different for each new Object
{} == {}
false
{x:5} == {x:5}
false
{x:5} === {x:5}
false
0 === false
false
0 == false
true
0 == 0
true
0 === 0
true
1 == 1
true
1 === 1
true
new Object() == new Object()
false
new Object() === new Object()
false
Object.create([]) === Object.create([])
false
Object.create([]) == Object.create([])
false
var x =””;
if(x){console.log(“123”)} else{console.log(“456”)}
456
var x = [];
if(x){console.log(“123”)} else{console.log(“456”)}
123
“” == 0
true
[] == “”
true
“” === 0
false
[] === “”
false
“” == ”
true
“” === ”
true
typeof(”)
“string”
typeof(“”)
“string”
” instanceof String
false
“” instanceof String
false
new String(“”) instanceof String
true
typeof(new String())
“object”
“”.toString == new String(“”)
false
“”.toString() == new String(“”)
true
“”.toString() == new String(“”).toString()
true
“”.toString === new String(“”)
false
“”.toString() === new String(“”)
false
“”.toString() === new String(“”).toString()
true
[] == new Array[];
VM362:1 Uncaught SyntaxError: Unexpected token ]
[] === new Array[];
VM363:1 Uncaught SyntaxError: Unexpected token ]
typeof(“”)
“string”
typeof(”)
“string”
typeof([])
“object”
typeof(Object)
“function”
typeof(new Array())
“object”
typeOf(new Array()) // typeOf is not defined, O in red is capital
VM418:1 Uncaught ReferenceError: typeOf is not defined(…)(anonymous function)
[].constructor.toString().indexOf(“Array”) > -1
true
[] instanceof Array
true
typeof null
“object”
typeof {}
“object”
{} instanceof Object
VM1270:1 Uncaught SyntaxError: Unexpected token instanceof
var t = {}
t instanceof Object
true
Object instanceof t
VM1385:1 Uncaught TypeError: Right-hand side of ‘instanceof’ is not callable(…)
typeof undefined
“undefined”
Note that typeof undefined is undefined which is wrapped in string quotes, but not a string.
typeof (typeof undefined)
“string”
Since the (inner) typeof undefined is undefined wrapped in string quotes, and the (outer) typeof (“undefined”) is being assumed as a string.
typeof when variable is defined.
var d = {};
typeof d === undefined
false
typeof d === “undefined”
false
d === “undefined”
false
d === undefined
false
typeof when variable is not defined
typeof u === undefined
false
typeof u === “undefined”
true
u === “undefined”
VM455:1 Uncaught ReferenceError: u is not defined
at <anonymous>:1:1
(anonymous) @ VM455:1
u === undefined
VM458:1 Uncaught ReferenceError: u is not defined
at <anonymous>:1:1
Numbers
1/-0 > 0
false
1/-0
-Infinity
-Infinity == 0
false
-Infinity > 0
false
-Infinity === 0
false
-Infinity > 1
false
-Infinity == 1
false
-Infinity === 1
false
Infinity == NaN
false
Infinity === NaN
false
1 instanceof Number
false
1/0 instanceof Number
false
1/0
Infinity
Infinity instanceof Number
false
typeof(“”)
“string”
typeof(Infinity)
“number”
new Number(1) instanceof Number
true
99.99 instanceof Number
false
typeof(99.99)
“number”
new Number(99.99) instanceof Number
true
typeof(NaN)
“number”
NaN instanceof Number
false
new Number(NaN)
Number {[[PrimitiveValue]]: NaN}
new Number(NaN) instanceof Number
true
NaN == Number
false
NaN === Number
false
new Number(NaN) === Number
false
new Number(NaN) == Number
false
NaN == undefined
false
NaN === undefined
false
NaN === ”
false
NaN == ”
false
NaN == null
false
NaN === null
false
isNaN(NaN)
true
Objects/Functions
var e = function(){};
var r = function(){};
var e1 = new e();
var r1 = new r();
e == r
false
e === r
false
typeof e
“function”
e instanceof function
VM352:1 Uncaught SyntaxError: Unexpected end of input
function instanceof e
VM387:1 Uncaught SyntaxError: Unexpected token instanceof
e1 == r1
false
e1 === r1
false
e1 instanceof r1
VM750:1 Uncaught TypeError: Right-hand side of ‘instanceof’ is not callable(…)(anonymous function) @ VM750:1
e1 instanceof Function
false
e1 instanceof Object
true
typeof(e1)
“object”
Assignments
var a = [1,2,3];
var b = [4,5,6];
a = b
[4, 5, 6] // This the value of a
a
[4, 5, 6] // a assignment to b copied over all values of b
b
[4, 5, 6] // No changes to b, so b still had reference to its original values
Pass by reference/value
var func = function(a) { var tempArray = [4,5,6]; a = tempArray; console.log(a);}
func([1,2,3]);
[4,5,6] // Even though we pass by reference with a different value, the assigned variable value would be overridden with internal assignment (if any).
http://stackoverflow.com/questions/899574/which-is-best-to-use-typeof-or-instanceof